Anatomy
Under the hood, a model has been trained with synchronised video and subtitle pairs and later used for predicating shifting offsets and directions under the guidance of a dual-stage aligning approach.
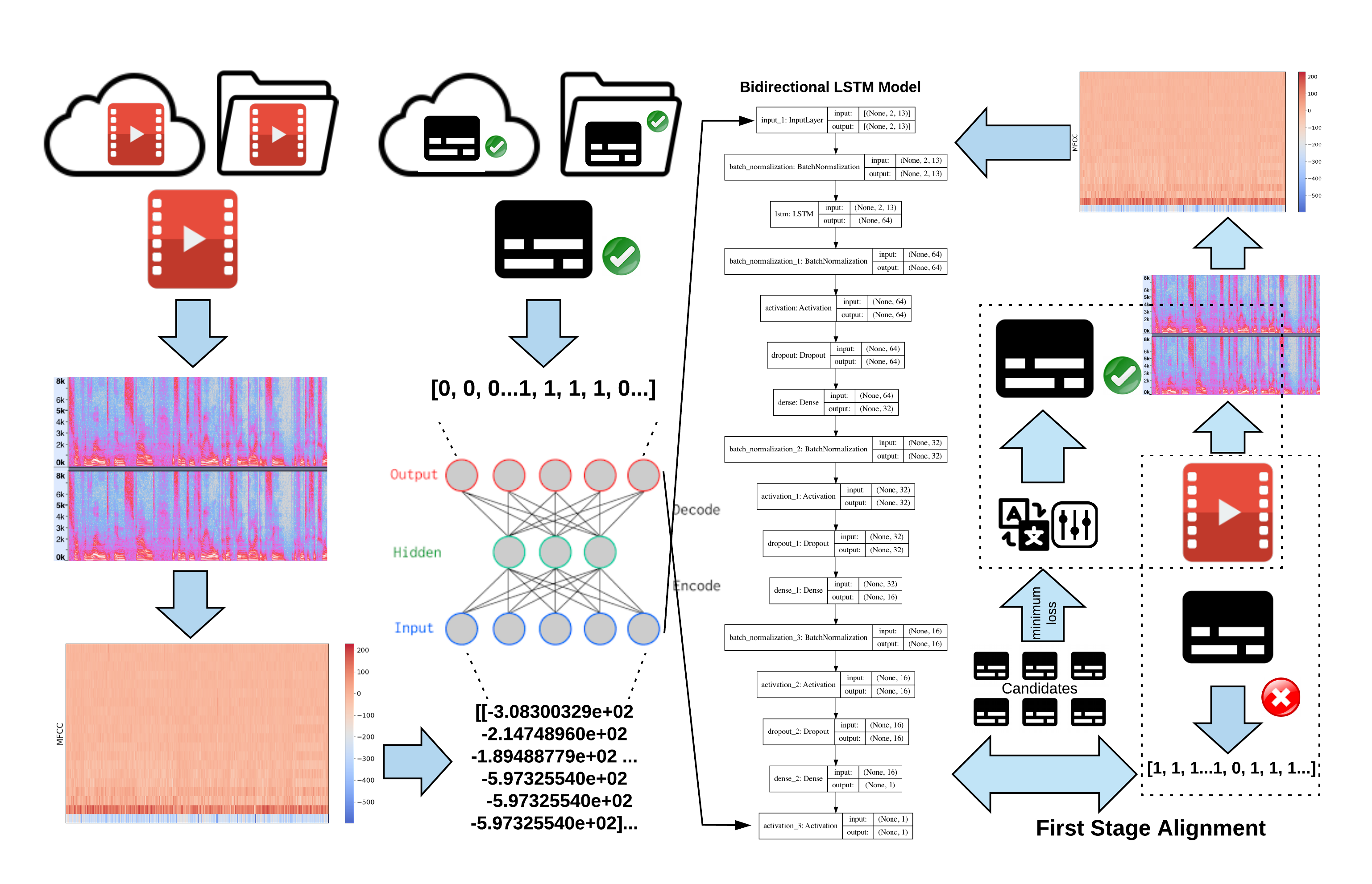
The following figure depicts the primary workflow of the first-stage subtitle alignment. It also includes upfront network training and later-on subtitle shifting. The data set used for training contains pairs of a video clip and a subtitle file with decent start and end time codes. Mel-Frequency Cepstral Coefficients are extracted in parallel and fed into a carefully designed DNN incorporating LSTM layers. For subtitle shifting, an out-of-sync subtitle file and a target video clip are fed in as input and the output can be either time offsets by which the subtitle should be shifted or a ready-to-playback subtitle file with calibrated start and end time. Notably, the shifting illustrated here leads to the completion of the first stage alignment (global shifting).
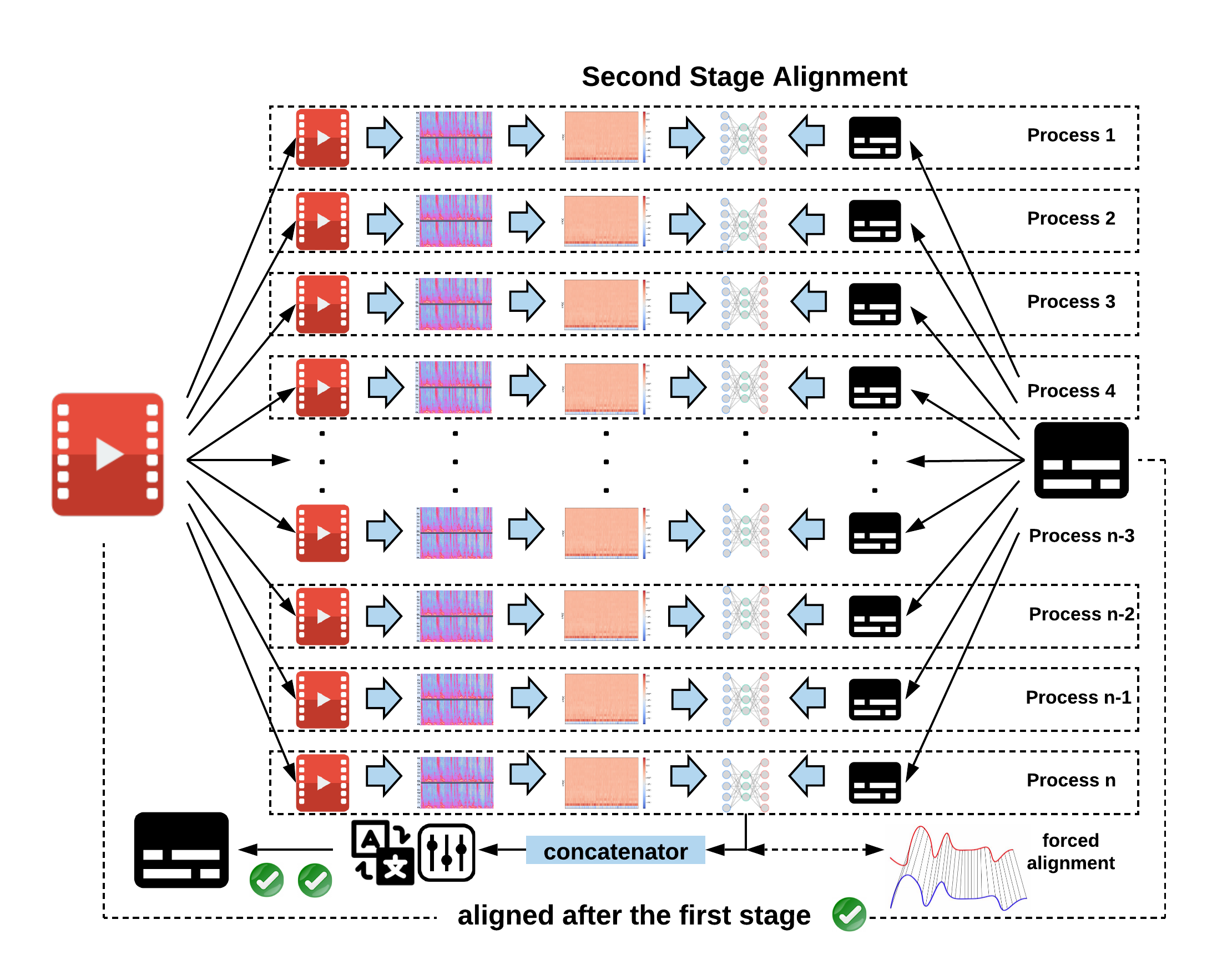
At the second stage, the target video clip and the globally shifted subtitle file will be broken down into evenly timed chunks respectively, each pair of which will be fed into the DNN and aligned in parallel (regional shifting) as shown in the following figure. And the concatenated subtitle chunks result in the final output.